Task ecologies and the evolution of world-tracking representations in large language models
Notes
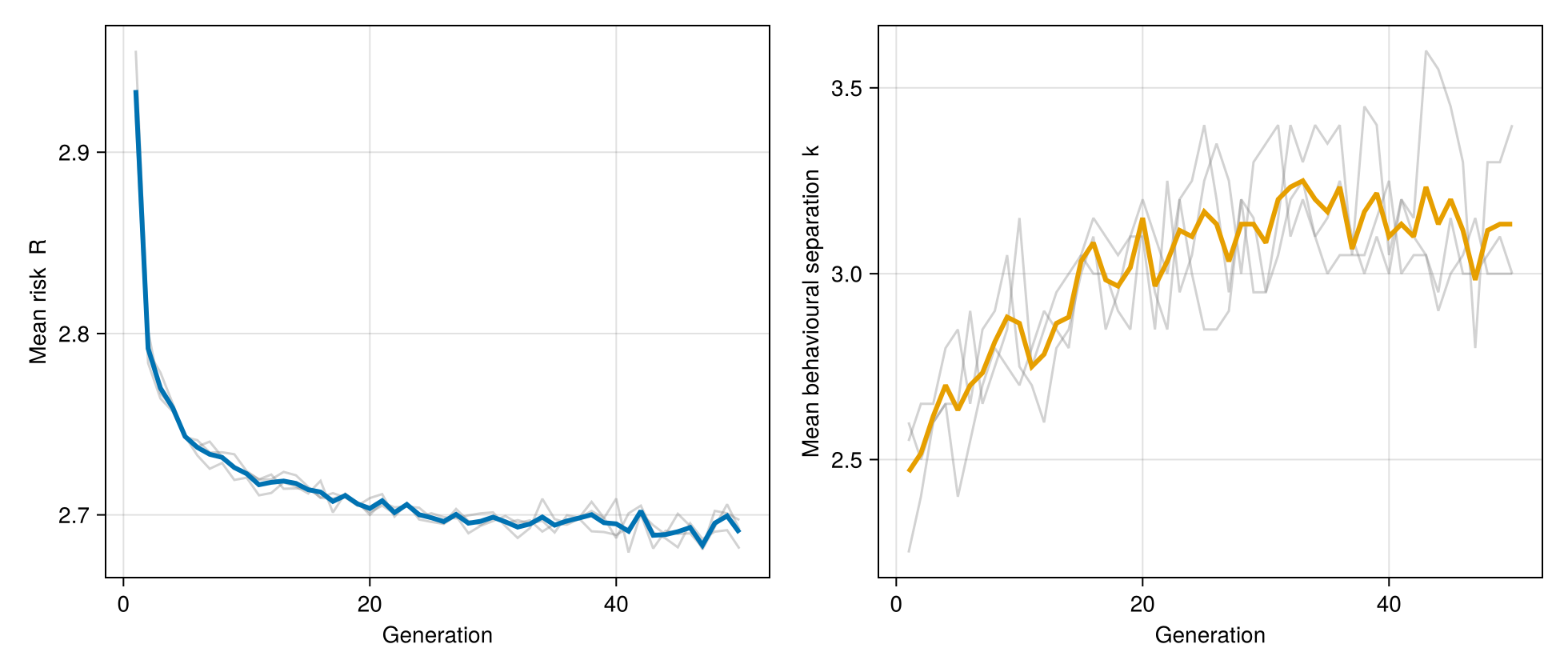
Large language models (LLMs) are increasingly used in settings where success depends on tracking conditions they have no direct access to, such as which language is being spoken, whether a claim is true, whether code will execute, or whether a plan is valid. Whether and how autoregressive models develop world-tracking representations is a broad open question. We address a specific, tractable formalization: which distinctions among latent world states must an optimal next-token encoding preserve, and under what conditions should populations of model lineages evolve toward such encodings? We answer the static question exactly. The Bayes-optimal token loss decomposes into an irreducible entropy floor plus the encoding's conditional insufficiency. Zero excess holds if and only if the encoding is sufficient, in the classical statistical sense, for the next token given the context. The relevant distinctions are determined by the training ecology: the unique coarsest sufficient encoding is the quotient partition by training-ecology equivalence, and it is also the entropy-minimizing zero-excess encoding. We call encodings that preserve all ecology-separated distinctions ecologically veridical. This yields three main consequences. First, under an explicit complexity regularizer, simplicity pressure preferentially merges low-gain distinctions. Second, models optimal for one ecology can still incur positive excess on richer deployment ecologies that refine it. Third, at the population level, if model lineages satisfy explicit heredity, variation, and differential-reproduction conditions, then inter-model selection acts on ecology-relative excess and should, in accessible mutation regimes, favor movement toward ecologically veridical encodings; post-training enters as ecology injection, with an explicit threshold for recovering gap distinctions. Exact finite-ecology calculations and controlled microgpt experiments validate the decomposition, the split-versus-merge threshold, off-ecology failure, and the two-ecology rescue mechanism in a regime where every quantity is observable. The aim is to use small language models as laboratory organisms for theory about representational targets under autoregressive prediction and the population-level pressures acting on model lineages.
References
No references yet.
Referenced by
- A Mathematical Framework for Transformer Circuits
- A Philosophical Introduction to Language Models – Part I: Continuity with Classic Debates
- A mathematical theory for understanding when abstract representations emerge in neural networks
- A model of inductive bias learning
- A new factor in evolution
- Agglomerative information bottleneck
- An Information-Geometric View of the Platonic Hypothesis
- An introduction to niche construction theory
- Between interface and truth: Multi-task selection drives ecologically veridical perception
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Climbing towards NLU: On meaning, form, and understanding in the age of data
- Comparing clusterings—an information based distance
- Completeness, similar regions, and unbiased estimation: Part I
- Convergence rates of posterior distributions
- Darwinian Populations and Natural Selection
- Do Large Language Models Understand Us?
- Do ML Models Represent Their Targets?
- Emergence of invariance and disentanglement in deep representations
- Emergent Introspective Awareness in Large Language Models
- High-dimensional asymptotics of feature learning: How one gradient step improves the representation
- How learning can guide evolution
- Information-theoretic analysis of generalization capability of learning algorithms
- Insights on representational similarity in neural networks with canonical correlation
- Language Models as Agent Models
- Learning and generalization with the information bottleneck
- Learning by Surprise: Surplexity for Mitigating Model Collapse in Generative AI
- Neural Networks can Learn Representations with Gradient Descent
- Neural networks as kernel learners: The silent alignment effect
- On the information bottleneck theory of deep learning
- Position: The Platonic Representation Hypothesis
- Revisiting the Platonic Representation Hypothesis: An Aristotelian view
- SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability
- Selection and covariance
- Show Your Work: Scratchpads for Intermediate Computation with Language Models
- Similarity of neural network representations revisited
- Sleeper agents: Training deceptive LLMs that persist through safety training
- Sufficiency and statistical decision functions
- The Vector Grounding Problem
- The benefit of multitask representation learning
- The debate over understanding in AI's large language models
- The deterministic information bottleneck
- The information bottleneck method
- The information bottleneck problem and its applications in machine learning
- The units of selection
- Toy Models of Superposition
- Understanding from Machine Learning Models
- Understanding with Toy Surrogate Models in Machine Learning
- When Models Manipulate Manifolds: The Geometry of a Counting Task
- microgpt